19.1. zookeeper¶
zookeeper(简称zk) 是apache hadoop的一个子项目, 它主要用来解决分布式应用中经常遇到的一些数据管理问题,比如统一命名服务、状态同步服务、集群管理、 分布式应用配置项的管理等。
19.1.1. zookeeper能提供什么¶
简单的说zookeeper = 文件系统 + 通知机制 。
文件系统说的是zookeeper存储数据以linux文件系统类似的方式组织。 通知机制说的是客户端监听它说关系的znode节点,当节点变化,zk会通知客户端。
zk中的节点不是目录或者文件, 而叫znode, znode可以看做目录使用和文件使用。 zk的znode按照是否持久,是否有序分为如下4种类型。
持久节点
持久顺序节点
临时节点
临时顺序节点
19.1.2. zookeeper的基本概念¶
19.1.2.1. 角色¶
zk的角色主要有一下三类角色,如下表所示:
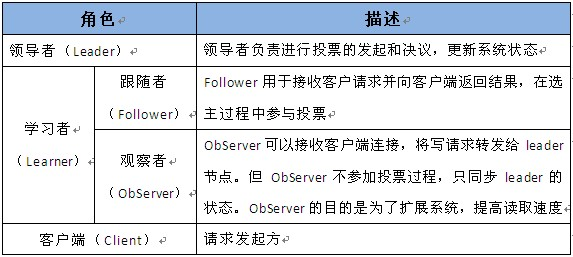
19.1.2.2. 工作原理¶
zk的核心是原子广播, 这个机制保证了各个server之间的同步,实现这个机制的协议叫做zab协议, zab协议有2个模式,分别是选主和同步。 当服务启动或者leader崩溃的时候,zab进入选主模式, 当leader选举出来,选主模式就结束了,状态同步确保了leader和server具有相同的状态。
为了保证食事务的顺序一致性, zk采用的事务id(zxid)来标识事务, 所有的提议都会加上zxid,它是一个64位的数字,高32位标识leader信息, 低32位标识递增计数。
19.1.2.3. 选主流程¶
zk的选主分情况的, 一个是全新集群的选主和运行中的集群再选举。 全新集群集群选主有分为2种, 顺序启动和一起启动2种情况。
- 全新集群顺序启动:
这里已5个节点为例, 启动顺序为node01到node05依次启动,
node01启动,找集群中leader, 没有,发起选举提议, 并把票投给了自己, 未过半,继续looking状态。
node02启动, 找集群的leader, 没有, 发起选举提议, 票给自己, node01,node02各个都一票, 发起重新投票, node01需要把票投给编号比自己大的。 node02 2票, node01 0票, 为过半, 继续looking状态。
node03启动, 找集群的leader,没有,发起选举提议, 票给自己, node03 1票, node02 2票, 都没有过半,重启投票,票给大的节点, node03 3票, 其他无票。node03 选为主节点。 node01, node02成为follower节点。
node04启动, 找集群的leader, 有, 成为follower节点。
node05启动, 找集群的leader, 有, 成为follower节点。
- 全新集群一起启动:
这里已5个节点的为例, 启动顺序一样的情况(内部还是有序的,只是时间相差很少。) 5个节点一起启动, 发动投票,情况也是比较多, 投票未过半就只能再投票, 如果触发再投票,越小的节点票数越少, 所以对应node01来说, 无论怎么投票都是无法拿到3票的。 node02来说, 最多能拿到自身一票和node01给自身的一票,也是无法达到3票的, node03来说, 还是可以拿到3票的, 几率还是比较低的。 全新的集群一起启动, 节点编号在半数以下的节点是无法成为主节点的, 只有半数以上的节点能成为主节点, 编号越高几率越高。
- 运行中的集群再选主:
这里主要参考如下几个指标zxid,数据最新,servierid最大。
19.1.2.4. 同步流程¶
选定leader之后, zk就进入了状态同步过程。
leader等待server连接。
follower连接leader,将最大的zxid发送给leader;
leader根据followser的zxid确定同步位点。
完成同步后通知follower,已经是update状态。
follow收到update消息后, 又可以重新接受client请求的连接,提供对外服务。
19.1.2.5. 角色职责¶
- leader:
恢复数据
维持与leader的心跳,接受leader的请求并判定leader的请求消息类型;
- follower:
向leader发送请求(ping,request,ack,revalidate)
接受leader消息并进行处理。
接受client的请求,如果写转给leader进行。
返回client结果。
observer相对比较特殊, 基本和follow一样,只是不参与leader发起的投票。
19.1.3. zookeeper可以做什么¶
19.1.3.1. 命名服务¶
命名服务通过指定名字来获取资源和服务的地址,简单的说zk做命名服务就是使用路径作为名字, 路径对应的数据作为具体的实体。 比如阿里巴巴的分布式服务框架dubbo就是使用zk作为命名服务, 服务提供者在启动的时候,向zk的指定节点/dubbo/${servername}/providers目录中写入自己的url地址,这个操作就是服务的发布。 服务的消费者启动的时候,订阅/dubbo/${servicename}/provides的目录下的提供者url地址,并向/dubbo/${servername}/consumers目录写入自己的url地址。
19.1.3.2. 配置管理¶
程序总是需要配置文件的, 如果程序部署在多个服务器上面,逐一修改会是非常痛苦的事情,使用zk可以在某个znode节点创建一个对应程序的配置目录,目录下放置这个程序的 所有配置,然后所有服务器节点对这个目录的节点和对应配置节点进行监听,这样每个程序都是可以收到zk的通知消息,及时自身节点的配置。
19.1.3.3. 集群管理¶
集群中主要2个事情需要zk来做, 服务器节点的退出和上线(上下线感知), 选举集群的master节点。
- 上下线感知:
所有的服务器节点约定一个父目录,并在其下创建 临时目录 ,然后每个节点都会监听这个父目录的 子节点个数 变化消息, 一旦机器挂了,zk上对应的数据就会删除(临时节点在断开连接时候自动删除节点) 这样父目录的子节点个数会变动, 监听此事件的所有服务器都会受到zk的通知。
- 选举master:
机器的master选举需要考虑的因素很多, 这里说一个相对简单的选举master方式, 所有服务器节点在一个父目录下创建临时的顺序编号的目录节点,每次选举就去编号最小的机器作为master就好。
19.1.3.4. 分布式锁¶
分布式中主要有3种锁,读锁、写锁、顺序锁。
- 读锁:
使用zk的临时的顺序编号就可以了, 每个client过来都会在特定目录下创建一个临时的节点,断开自动删除自身节点。
- 写锁:
使用zk的临时的节点就可以了, client过来会在尝试在特定的目录下创建一个临时节点,如果能成功就可以继续写操作, 如果失败需要监听此节点的删除事件,如果收到通知就继续前面操作。
- 顺序锁:
使用zk的临时顺序节点就可以了, client过来会在特定的目录下面创建一个临时顺序节点,zk来控制最小的顺序获得锁,一直循环下去。
19.1.3.5. 队列管理¶
这里有2种队列, 一个是同步队列, 一个是fifo队列。
- 同步队列:
所有client约定一个目录下,都创建一个临时的顺序节点,都监听父目录, 如果节点个数达到对应的个数的时候, 就说明所有节点到达了, 就可以继续处理接下里的同步工作了。
- fifo队列:
这个基本上面的顺序锁差不多, 需要入列有编号, 出列有编号。 client过来的时候会在特定目录下创建一个临时的编号节点, 因为zk的节点编号从小到大, 只有zk每次选择节点的时候选择到具体的最小编号的就可以 保证fifo的。
19.1.4. zookeeper的安装¶
# 安装java
[root@centos-152 ~]# wget http://download.oracle.com/otn-pub/java/jdk/8u162-b12/0da788060d494f5095bf8624735fa2f1/jdk-8u162-linux-x64.rpm?AuthParam=1522289893_92e84e76f51bb5aa8133b08fcf86150b
[root@centos-152 ~]# ls
anaconda-ks.cfg jdk-8u162-linux-x64.rpm?AuthParam=1522289893_92e84e76f51bb5aa8133b08fcf86150b
[root@centos-152 ~]# mv jdk-8u162-linux-x64.rpm\?AuthParam\=1522289893_92e84e76f51bb5aa8133b08fcf86150b jdk-8u162-linux-x64.rpm
[root@centos-152 ~]# yum install jdk-8u162-linux-x64.rpm
# 验证java
[root@centos-152 java]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz -P /usr/local/src/
tar zxvf zookeeper-3.4.8.tar.gz -C /opt
cd /opt && mv zookeeper-3.4.8 zookeeper
cd zookeeper
cp conf/zoo_sample.cfg conf/zoo.cfg
vim conf/zoo.cfg
# 主要修改如下几项
dataDir=/opt/zookeeper/data
# 新增如下几行
server.1= 192.168.1.151:2888:3888
server.2= 192.168.1.152:2888:3888
server.3= 192.168.1.153:2888:3888
# 启动前确保对应的目录都是存在的。
echo "1" > /opt/zookeeper/data/myid
# 启动
/opt/zookeeper/bin/zkServer.sh start
# 查看状态
/opt/zookeeper/bin/zkServer.sh status